订阅 付费边界 访问管理策略的边界
影响成本的因素:资源类型 服务 位置
pricing carculator 产品定价计算器和总拥有成本计算器
降低成本:
- 执行成本分析
- 使用Azure顾问监视使用情况
- 使用支出限制
- 使用Azure预订 提前付款产品
- 选择低成本地点和地区
- 使用标签标识成本所有者
cost manage工具
改进应用程序SLA 承诺的性能目标 如某级别月累计停机时间不超过xxx
云计算概览
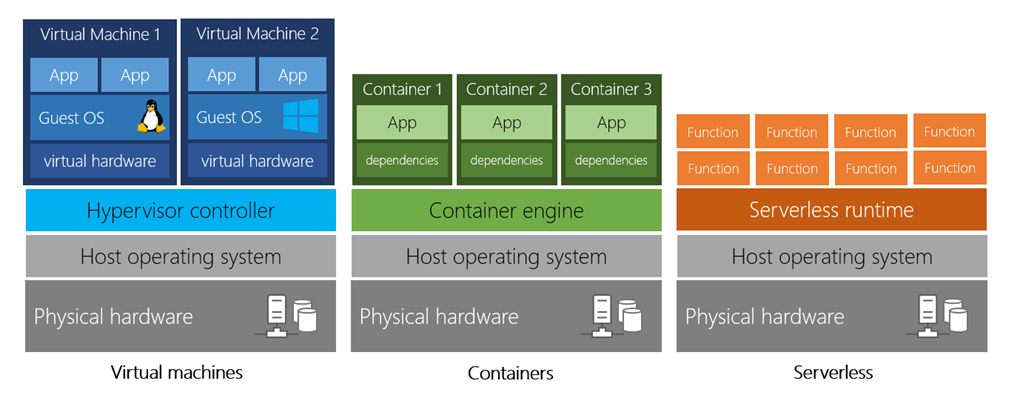
自称:经济高效、可缩放、具有弹性、始终保持最新状态、可靠且安全
- 资本支出 (Capital Expenditure, CapEx)实体基础设施投入费用, 如服务器、存储、网络、备份、灾后重建、技术人员
- 运营支出 (Operational Expenditure, OpEx) 服务/产品使用费用
issue: 测试从Azure Serveice 到 remote DB server的network connections
背景:老板要将正在开发的项目放到公网可以访问的服务器上以用来演示,迁移数据库到云端是费事且有额外成本的。
日前的实践找到了控制台的解决方法 创建App Service后其管理面板上Development Tools--SSH,其进入后是linux终端,路径在wwwroot下,常用网络连接工具见{% post-link LinuxTools Linux命令行工具 %} curl命令可用
benefit
The public cloud is a shared entity whereby multiple corporations each use a portion of the resources in the cloud. It is the benefit of using a public cloud service for the servers over an on-premises network
混合云(Hybrid Cloud)
公有云的缺点:使用公有云可能无法满足特定的安全要求;公有云可能无法满足政府政策、行业标准或法律要求;不拥有硬件或服务,也无法按照你的意愿管理它们;可能很难满足独特的业务需求,例如必须维护旧版应用程序
私有云服务和公有云服务的结合,即要架设开放的商用应用,又对部分资源存在硬件或自主管理方面的要求,宜选择私有云
例题:Suppose you have two types of applications: legacy applications that require specialized mainframe hardware and newer applications that can run on commodity hardware. Which cloud deployment model would be best for you?
A. Public cloud
B. Private cloud
C. Hybrid cloud
保留预置的(on-premise)服务器,并且扩展需求,宜选择混合云,即保留原服务器以消除迁移成本,且用公有平台(或其他资源)进行方便的扩展
例题:You have an on-premises network that contains 100 servers.
You need to recommend a solution that provides additional resources to your users. The solution must minimize capital and operational expenditure costs.
A. a complete migration to the public cloud
B. an additional data center
C. a private cloud
D. a hybrid cloud
极具争议的一道判断题:An organization that hosts its infrastructure in a private cloud can decommission its data center.
答案是False. 希望不要在考场上遇到这么坑爹的表述,题干问如果organization在私有云上架设自己的设施,那他自己数据中心是不可或缺的还是可以decommission(拆除),其想表达的是如果你用公有云或者混合云,就没有必要自己经营数据中心了。
IaaS PaaS SaaS
Infrastructure as a service (IaaS) is an instant computing infrastructure, provisioned and managed over the internet. It’s one of the four types of cloud services, along with software as a service (SaaS), platform as a service (PaaS), and serverless.

IaaS 通常用于以下场景:迁移工作负载;测试和开发;存储、备份和恢复。
Caution! 虚拟机是IaaS
例题:Your company plans to migrate all its data and resources to Azure.
The company’s migration plan states that only platform as a service (PaaS) solutions must be used in Azure.
You need to deploy an Azure environment that supports the planned migration.
Solution: You create an Azure App Service and Azure SQL databases.
A: Correct. Azure SQL databases 也属于 PaaS,区别于在虚拟机中安装的SQL Server(IaaS)
例题:Your company plans to migrate all its data and resources to Azure.
The company’s migration plan states that only Platform as a Service (PaaS) solutions must be used in Azure.
You need to deploy an Azure environment that meets the company migration plan.
Solution: You create an Azure App Service and Azure Storage accounts.
A: False. Azure Storage accounts is IaaS
Cosmos DB is PaaS
区域、中心
Q:Deploying an app can be done directly to what level of physical granularity(尺度)? A:Region
You need to ensure that the services running on the virtual machines are available if a single data center fails.
Solution: You deploy the virtual machines to two or more regions.
or You deploy the virtual machines to two or more availability zones
区域间数据传输根据带宽收费
Azure availability zone can be used to protect access to Azure services from an Azure data center failure
计价
例题:If you create two Azure virtual machines that use the B2S size, each virtual machine will always generate the same monthly costs.(False)
Two virtual machines using the same size could have different disk configurations. Therefore, the monthly
costs could be different.
“pay-as-you-go”
When planning to migrate a public website to Azure, you must plan to pay monthly usage costs. .
“elasticity”
弹性计算, 系统监控工具控制,无需中断操作即可使分配的资源量与实际所需资源量相匹配。通过云灵活性,公司可避免就未用容量或闲置资源付费,且不必担心投入资金购买或维护额外的资源和设备。
订阅
An Azure AD tenant can have multiple subscriptions but an Azure subscription can only be associated with one Azure AD tenant.
见将 Azure 订阅关联或添加到 Azure Active Directory 租户
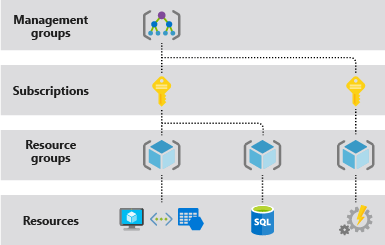
资源组
A resource can interact with resources in other resource groups
Deleting the resource group will remove the resource group as well as all the resources in that resource group.
Resources from multiple different regions can be placed in a resource group.
- 资源组中的所有资源应该具有相同的生命周期。 一起部署、更新和删除这些资源。
- 每个资源只能存在于一个资源组中。可以将资源从一个资源组移到另一个组
- 资源组中的资源可以位于与资源组不同的区域。
锁定资源以防止意外:
CanNotDelete和ReadOnly, 资源可以存在多个删除锁,自动继承上层锁。
Azure virtual machines should you use from the Azure portal to view service failure notifications that can
affect the availability of VM1(your virtual machine)?
例题:You need to view a list of planned maintenance events that can affect the availability of an Azure subscription.
On the Help and Support blade, there is a Service Health option. If you click Service Health, a new blade opens. The Service Health blade contains the Planned Maintenance link which opens a blade where you can view a list of planned maintenance events that can affect the availability of an Azure subscription.
Azure服务
An integrated solution for the deployment of code - Azure DevOps
A tool that provides guidance and recommendation to improve an Azure environment - zure Advisor
A simplified tool to build intelligent Artificial Intelligence (AI) applications - Azure Cognitive services
Monitors web applications - Azure Application Insights
规模集(scale set)
如用于创建并管理一组负载均衡的 VM,根据需求或定义的计划自动增减 VM 实例的数目,为应用程序提供搞可用性
DevTest Lab
开发测试实验室,利用基架/模板快速创建环境
存储账户
Data that is copied to Azure Storage account is maintained automatically in at least three copies.
存储账户的数据冗余选项有4个 每种都以不同的措施复制三次 见存储帐户概述
Cloud shell
Cloud shell就是页面上那个命令行工具,从中可以运行PowerShell命令或Bash命令
另install azure cli then it can be used in Command Prompt or Windows PowerShell
例题:An Azure administrator plans to run a PowerShell script that creates Azure resources. You need to recommend which computer configuration to use to run the script.
Solution: Run the script from a computer that runs Linux and has the Azure CLI tools installed.
Does this meet the goal?
answer:A PowerShell script is a file that contains PowerShell cmdlets and code. A PowerShell script needs to be run in PowerShell.
PowerShell can now be installed on Linux. However, the question states that the computer has Azure CLI tools, not PowerShell installed. Therefore, this solution does not meet the goal.
PowerShell已经是跨平台应用,可以装在linux,azure cli是command line interface可以认为是命令集合,依托于windows cmd或powershell。上面的题目想说powershell脚本运行基于powershell应用而不是azure cli package,私以为题目很无聊。
官方教程的练习:
What do you need to install on your machine to let you execute Azure CLI commands locally?
A.The Azure cloud shell B.The Azure CLI and Azure PowerShell C.Only the Azure CLI
- True or false: The Azure CLI can be installed on Linux, macOS, and Windows, and the CLI commands you use are the same in all platforms.
A.True B.False
- Which parameter can you add to most CLI commands to get concise, formatted output?
A.list B.table C.group
answer is C A B
Azure命令行没有ping,而使用tcpping
Data Lake
例题:You plan to store 20 TB of data in Azure. The data will be accessed infrequently and visualized by using Microsoft Power BI.
You need to recommend a storage solution for the data.
A. Azure Data Lake
B. Azure Cosmos DB
C. Azure SQL Data Warehouse
D. Azure SQL Database
E. Azure Database for PostgreSQL
answer is AC,Azure Data Lake
网络
Local Network Gateway 创建从azure到本地网关的连接
You have an Azure environment that contains 10 virtual networks and 100 virtual machines.
You need to limit the amount of inbound traffic to all the Azure virtual networks.
What should you create?
A. one application security group (ASG)
B. 10 virtual network gateways
C. 10 Azure ExpressRoute circuits
D. one Azure firewall
answer is D
Advanced
2020.9.26勉强通过 准备AZ-303 + AZ-304 即成为Azure Solutions Architect Expert
It certainly wouldn’t hurt you to have your Microsoft Azure Administrator in the bag before attempting to take down this colossal certification and its dual architecture-focused exams. ————《Which Azure certification is right for me?》
即建议通过AZ-104获得Azure Administrator Associate认证,难度只有两星,费用是115刀
知乎:Azure 框架设计师认证考试2020大更改
原AZ-103将被新的AZ-104替代,原AZ-300将被新的AZ-303替代,原AZ-301将被新的AZ-304替代
AZ-103的考试侧重点分配如下
管理 Azure 订阅和资源 (15-20%)
实施和管理存储 (15-20%)
部署和管理虚拟机 (VM) (15-20%)
配置和管理虚拟网络 (30-35%)
管理身份 (15-20%)
在新的AZ-104中,这些权重将会有一些修改。
订阅Subscription和身份认证Identity将会合并成单独的身份认证Identity
新增考点监控和备份(Monitor and Backup)
新增主题: 网络程序和容器(Web apps and containers)
Two ways to prepare 见页面下方官方文档
AZ-300的考试权重分配如下
- 部署和配置基础设施 (25-30%)
- 实现工作负载和安全 (20-25%)
- 创建和部署 App (5-10%)
- 实现认证和安全数据(5-10%)
- 开发云和 Azure 存储 (20-25%)
在新的AZ-303中,这些权重将会有一些修改。
- 考试中有50%的部分是关于部署和配置(Deploy and Configure)
- 去掉了对认证和安全数据的要求
- 去掉了对云开发:消息和自动扩展的要求
- 新增部署数据平台的要求,包括SQL DB和Cosmos DB
- 新增监控的要求 Monitoring
Two ways to prepare 见页面下方官方文档
AZ-301的考试权重分配如下
- 确定工作量要求 (10-15%)
- 设计身份和安全性 (20-25%)
- 设计数据平台解决方案 (15-20%)
- 设计业务连续性策略(15-20%)
- 部署、迁移和集成设计(10-15%)
- 设计基础设施策略(15-20%)
在新的AZ-304中,这些权重将会有一些修改。
- 去掉获取信息和要求的部分
- 去掉设计认证管理的部分
- 去掉危险预防策略的部分
- 去掉数据文档流的部分
- 去掉数据保护策略的部分
- 去掉数据监控策略的部分
- 去掉存储策略的部分
- 添加设计程序框架
Two ways to prepare 见页面下方官方文档